OS segmentation
December 27, 2015
Previously, I had boot the trivial Multiboot kernel. Despite it was really fun, I need more than just showing a letter on a screen. My goal is to write a simple kernel with Unix-ready userspace.
I have been writing my kernel for the last couple of months (on and off) and with help of OSDev wiki I got a quite good kernel based on meaty skeleton and now I want to go further. But where to? My milestone is to make keyboard input working. This will require working interrupts, but it’s not the first thing to do.
According to Multiboot specification after bootloader passed the control to our kernel, the machine is in pretty reasonable state except 3 things (quoting chapter 3.2. Machine state):
- ‘ESP’ - The OS image must create its own stack as soon as it needs one.
- ‘GDTR’ - Even though the segment registers are set up as described above, the ‘GDTR’ may be invalid, so the OS image must not load any segment registers (even just reloading the same values!) until it sets up its own ‘GDT’.
- ‘IDTR’ The OS image must leave interrupts disabled until it sets up its own IDT.
Setting up a stack is simple - you just put 2 labels divided by your stack size. In “hydra” it’s 16 KiB:
# Reserve a stack for the initial thread.
.section .bootstrap_stack, "aw", @nobits
stack_bottom:
.skip 16384 # 16 KiB
stack_top:
Next, we need to setup segmentation. We have to do this before setting up interrupts because each IDT descriptor gate must contain segment selector for destination code segment - a kernel code segment that we must setup.
Nevertheless, it almost certainly will work even without setting up GDT because Multiboot bootloader sets it by itself and we left with its configuration that usually will set up flat memory model. For example, here is the GDT that legacy grub set:
| Index | Base | Size | DPL | Info |
|---|---|---|---|---|
| 00 (Selector 0x0000) | 0x0 |
0xfff0 |
0 | Unused |
| 01 (Selector 0x0008) | 0x0 |
0xffffffff |
0 | 32-bit code |
| 02 (Selector 0x0010) | 0x0 |
0xffffffff |
0 | 32-bit data |
| 03 (Selector 0x0018) | 0x0 |
0xffff |
0 | 16-bit code |
| 04 (Selector 0x0020) | 0x0 |
0xffff |
0 | 16-bit data |
It’s fine for kernel-only mode because it has 32-bit segments for code and data of size 232, but no segments with DPL=3 and also 16-bit code segments that we don’t want.
But really it is just plain stupid to rely on undefined values, so we set up segmentation by ourselves.
Segmentation on x86
Segmentation is a technique used in x86 CPUs to expand the amount of available memory. There are 2 different segmentation models depending on CPU mode - real-address model and protected model.
Segmentation in Real mode
Real mode is a 16-bit Intel 8086 CPU mode, it’s a mode where processor starts
working upon reset. With a 16-bit processor, you may address at most
216 = 64 KiB of memory which even by the times of 1978 was way too
small. So Intel decided to extend address space to 1 MiB and made address bus 20
bits wide (220 = 1048576 bytes = 1 MiB). But you can’t address
20 bits wide address space with 16-bit registers, you have to expand your
registers by 4 bits. This is where segmentation comes in.
The idea of segmentation is to organize address space in chunks called segments, where your address from 16-bit register would be an offset in the segment.
With segmentation, you use 2 registers to address memory: segment register and general-purpose register representing offset. Linear address (the one that will be issued on the address bus of CPU) is calculated like this:
Linear address = Segment << 4 + Offset
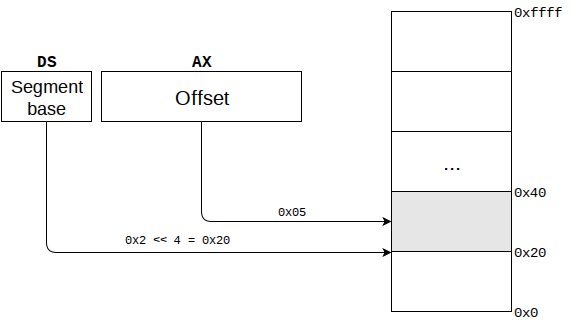
Note, that with this formula it’s up to you to choose segments size. The only
limitation is that segments size is at least 16 bytes, implied by 4 bit shift,
and the maximum of 64 KiB implied by Offset size.
In the example above we’ve used logical address 0x0002:0x0005 that gave us
linear address 0x00025. In my example I’ve chosen to use 32 bytes segments,
but this is only my mental representation - how I choose to construct logical
addresses. There are many ways to represent the same address with segmentation:
0x0000:0x0025 = 0x0 << 4 + 0x25 = 0x00 + 0x25 = 0x00025
0x0002:0x0005 = 0x2 << 4 + 0x05 = 0x20 + 0x05 = 0x00025
0xffff:0x0035 = 0xffff0 + 0x35 = 0x100025 = (Wrap around 20 bit) = 0x00025
0xfffe:0x0045 = 0xfffe0 + 0x45 = 0x100025 = (Wrap around 20 bit) = 0x00025
...
Note the wrap around part. this is where it starts to be complicated and it’s time to tell the fun story about Gate-A20.
On Intel 8086, segment register loading was a slow operation, so some DOS programmers used a wrap-around trick to avoid it and speed up the programs. Placing the code in high addresses of memory (close to 1MiB) and accessing data in lower addresses (I/O buffers) was possible without reloading segment thanks to wrap-around.
Now Intel introduces 80286 processor with 24-bit address bus. CPU started in real mode assuming 20-bit address space and then you could switch to protected mode and enjoy all 16 MiB of RAM available for your 24-bit addresses. But nobody forced you to switch to protected mode. You could still use your old programs written for the Real mode. Unfortunately, 80286 processor had a bug - in the Real mode it didn’t zero out 21st address line - A20 line (starting from A0). So the wrap-around trick was not longer working. All those tricky speedy DOS programs were broken!
IBM that was selling PC/AT computers with 80286 fixed this bug by inserting logic gate on A20 line between CPU and system bus that can be controlled from software. On reset BIOS enables A20 line to count system memory and then disables it back before passing control to operating CPU, thus enabling wrap-around trick. Yay! Read more shenanigans about A20 here.
So, from now on all x86 and x86_64 PCs has this Gate-A20. Enabling it is one of the required things to switch into protected mode.
Needless to say that Multiboot compatible bootloader enables it and switching into protected mode before passing control to the kernel.
Segmentation in Protected mode
As you might saw in the previous section, segmentation is an awkward and error-prone mechanism for memory organization and protection. Intel had understood it quickly and in 80386 introduced paging - flexible and powerful system for real memory management. Paging is available only in protected mode - successor of the real mode that was introduced in 80286, providing new features in segmentation like segment limit checking, read-only and execute-only segments and 4 privilege levels (CPU rings).
Although paging is the mechanism for memory management when operating in protected mode all memory references are subject of segmentation for the sake of backward compatibility. And it drastically differs from segmentation in real mode.
In protected mode, instead of segment base, segment register holds a segment selector, a value used to index segments table called Global Descriptor Table (GDT). This selector chooses an entry in GDT called Segment Descriptor. Segment descriptor is an 8 bytes structure that contains the base address of the segment and various fields used for various design choices howsoever exotic they are.

GDT is located in memory (on 8 bytes boundary) and pointed by gdtr
register.
All memory operations either explicitly or implicitly contain segment registers. CPU uses the segment register to fetch segment selector from GDT, finds out that segment base address and add offset from memory operand to it.
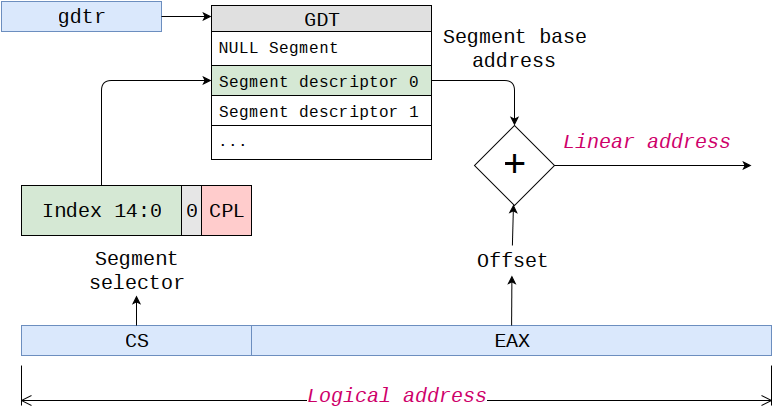
You can mimic real-mode segmentation model by configuring overlapping segments. And actually, absolutely most of operating systems do this. They setup all segments from 0 to 4 GiB, thus fully overlapping and carry out memory management to paging.
How to configure segmentation in protected mode
First of all, let’s make it clear - there is a lot of stuff. When I was reading Intel System programming manual, my head started hurting. And actually, you don’t need all this stuff because it’s segmentation and you want to set it up so it will just work and prepare the system for paging.
In most cases, you will need at least 4 segments:
- Null segment (required by Intel)
- Kernel code segment
- Kernel data segment
- Userspace code segment
- Userspace data segment
This structure not only sane but is also required if you want to use
SYSCALL/SYSRET - fast system call mechanism without CPU exception overhead
of int 0x80.
These 4 segments are “non-system”, as defined by a flag S in segment
descriptor. You use such segments for normal code and data, both for kernel and
userspace. There are also “system” segments that have special meaning for CPU.
Intel CPUs support 6 system descriptors types of which you should have at least
one Task-state segment (TSS) for each CPU (core) in the system. TSS is used to
implement multi-tasking and I’ll cover it in later articles.
Four segments that we set up differs in flags. Code segments are execute/read only, while data segments are read/write. Kernel segments differ from userspace by DPL - descriptor privilege level. Privilege levels form CPU protection rings. Intel CPUs have 4 rings, where 0 is the most privileged and 3 is least privileged.
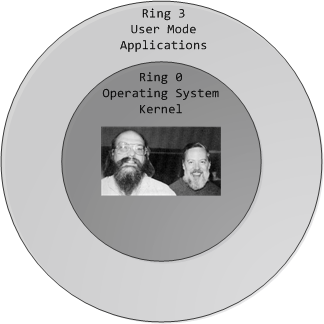
CPU rings is a way to protect privileged code such as operating system kernel from direct access of wild userspace. Usually, you create kernel segments in a ring 0 and userspace segments in ring 3. It’s not that it’s impossible to access kernel code from userspace, it is, but there is a well-defined, controlled by the kernel, mechanism involving (among other things) switch from ring 3 to ring 0.
Besides DPL (descriptor privilege level) that is stored in segment descriptor itself there are also CPL (Current Privilege Level) and RPL (Requested Privilege Level). CPL is stored in CS and SS segment registers. RPL is encoded in segment selector. Before loading segment selector into segment register CPU performs privilege check, using this formula
MAX(CPL, RPL) <= DPL
Because RPL is under calling software control, it may be used to tamper privileged software. To prevent this CPL is used in access checking.
Let’s look how control is transferred between code segments. We will look into the simplest case of control transfer with far jmp/call, Special instructions SYSENTER/SYSEXIT, interrupts/exceptions and task switching is another topic.
Far jmp/call instructions in contrast to near jmp/call contain segment selector as part of the operand. Here are examples
jmp eax ; Near jump
jmp 0x10:eax ; Far jump
When you issue far jmp/call CPU takes CPL from CS, RPL from segment selector encoded into far instruction operand and DPL from target segment descriptor that is found by offset from segment selector. Then it performs privilege check. If it was successful, segment selector is loaded into the segment register. From now you’re in a new segment and EIP is an offset in this segment. Called procedure is executed in its own stack. Each privilege level has its own stack. Fourth privilege level stack is pointed by SS and ESP register, while stack for privilege levels 2, 1 and 0 is stored in TSS.
Finally, let’s see how it’s all working.
As you might saw, things got more complicated and conversion from logical to linear address (without paging it’ll be physical address) now goes like this:
- Logical address is split into 2 parts: segment selector and offset
- If it’s not a control transfer instruction (far jmp/call, SYSENTER/SYSCALL, call gate, TSS or task gate) then go to step 8.
- If it’s a control transfer instruction then load CPL from CS, RPL from segment selector and DPL from descriptor pointed by segment selector.
- Perform access check:
MAX(CPL,RPL) <= DPL. - If it’s not successful, then generate
#GFexception (General Protection Fault) - Otherwise, load segment register with segment selector.
- Fetch based address, limit and access information and cache in hidden part of segment register
- Finally, add current segment base address taken from segment register (actually cached value from hidden part of segment register) and offset taken from the logical address (instruction operand), producing the linear address.
Note, that without segments switching address translation is pretty straightforward: take the base address and add offset. Segment switching is a real pain, so most operating systems avoids it and set up just 4 segments - minimum amount to please CPU and protect the kernel from userspace.
Segments layout examples
Linux kernel
Linux kernel describes segment descriptor as desc_struct structure in arch/x86/include/asm/desc_defs.h
struct desc_struct {
union {
struct {
unsigned int a;
unsigned int b;
};
struct {
u16 limit0;
u16 base0;
unsigned base1: 8, type: 4, s: 1, dpl: 2, p: 1;
unsigned limit: 4, avl: 1, l: 1, d: 1, g: 1, base2: 8;
};
};
} __attribute__((packed));
#define GDT_ENTRY_INIT(flags, base, limit) { { { \
.a = ((limit) & 0xffff) | (((base) & 0xffff) << 16), \
.b = (((base) & 0xff0000) >> 16) | (((flags) & 0xf0ff) << 8) | \
((limit) & 0xf0000) | ((base) & 0xff000000), \
} } }
GDT itself defined in arch/x86/kernel/cpu/common.c:
.gdt = {
[GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xc09a, 0, 0xfffff),
[GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc092, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xc0fa, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f2, 0, 0xfffff),
...
Basically, there is a flat memory model with 4 segments from 0 to 0xfffff * granularity, where granularity flag set to 1 specifies 4096 increments, thus
giving us the limit of 4 GiB. Userspace and kernel segments differ in DPL only.
First Linux version 0.01
In the Linux version 0.01, there were no userspace segments. In boot/head.s
_gdt: .quad 0x0000000000000000 /* NULL descriptor */
.quad 0x00c09a00000007ff /* 8Mb */
.quad 0x00c09200000007ff /* 8Mb */
.quad 0x0000000000000000 /* TEMPORARY - don't use */
.fill 252,8,0 /* space for LDT's and TSS's etc */
Unfortunately, I wasn’t able to track down how userspace was set up (TSS only?).
NetBSD
NetBSD kernel defines 4 segments as everybody. In sys/arch/i386/include/segments.h
#define GNULL_SEL 0 /* Null descriptor */
#define GCODE_SEL 1 /* Kernel code descriptor */
#define GDATA_SEL 2 /* Kernel data descriptor */
#define GUCODE_SEL 3 /* User code descriptor */
#define GUDATA_SEL 4 /* User data descriptor */
...
Segments are set up in
sys/arch/i386/i386/machdep.c,
function initgdt:
setsegment(&gdt[GCODE_SEL].sd, 0, 0xfffff, SDT_MEMERA, SEL_KPL, 1, 1);
setsegment(&gdt[GDATA_SEL].sd, 0, 0xfffff, SDT_MEMRWA, SEL_KPL, 1, 1);
setsegment(&gdt[GUCODE_SEL].sd, 0, x86_btop(I386_MAX_EXE_ADDR) - 1,
SDT_MEMERA, SEL_UPL, 1, 1);
setsegment(&gdt[GUCODEBIG_SEL].sd, 0, 0xfffff,
SDT_MEMERA, SEL_UPL, 1, 1);
setsegment(&gdt[GUDATA_SEL].sd, 0, 0xfffff,
SDT_MEMRWA, SEL_UPL, 1, 1);
Where setsegment has following
signature:
void
setsegment(struct segment_descriptor *sd, const void *base, size_t limit,
int type, int dpl, int def32, int gran)
OpenBSD
Similar to NetBSD, but segments order is different. In sys/arch/i386/include/segments.h:
/*
* Entries in the Global Descriptor Table (GDT)
*/
#define GNULL_SEL 0 /* Null descriptor */
#define GCODE_SEL 1 /* Kernel code descriptor */
#define GDATA_SEL 2 /* Kernel data descriptor */
#define GLDT_SEL 3 /* Default LDT descriptor */
#define GCPU_SEL 4 /* per-CPU segment */
#define GUCODE_SEL 5 /* User code descriptor (a stack short) */
#define GUDATA_SEL 6 /* User data descriptor */
...
As you can see, userspace code and data segments are at positions 5 and 6 in
GDT. I don’t know how SYSENTER/SYSEXIT will work here because you set the
value of SYSENTER segment in IA32_SYSENTER_CS MSR. All other segments are
calculated as an offset from this MSR, e.g. SYSEXIT target segment is a 16 bytes
offset - GDT entry that is after next to SYSENTER segment. In this case,
SYSEXIT will hit LDT. Some help from OpenBSD kernel folks will be great here.
Everything else is same.
xv6
xv6 is a re-implementation of Dennis Ritchie’s and Ken Thompson’s Unix Version 6 (v6). It’s a small operating system that is taught at MIT.
It’s really pleasant to read it’s source code. There is a
main in main.c
that calls seginit in
vm.c
This function sets up 6 segments:
#define SEG_KCODE 1 // kernel code
#define SEG_KDATA 2 // kernel data+stack
#define SEG_KCPU 3 // kernel per-cpu data
#define SEG_UCODE 4 // user code
#define SEG_UDATA 5 // user data+stack
#define SEG_TSS 6 // this process's task state
like this
// Map "logical" addresses to virtual addresses using identity map.
// Cannot share a CODE descriptor for both kernel and user
// because it would have to have DPL_USR, but the CPU forbids
// an interrupt from CPL=0 to DPL=3.
c = &cpus[cpunum()];
c->gdt[SEG_KCODE] = SEG(STA_X|STA_R, 0, 0xffffffff, 0);
c->gdt[SEG_KDATA] = SEG(STA_W, 0, 0xffffffff, 0);
c->gdt[SEG_UCODE] = SEG(STA_X|STA_R, 0, 0xffffffff, DPL_USER);
c->gdt[SEG_UDATA] = SEG(STA_W, 0, 0xffffffff, DPL_USER);
// Map cpu, and curproc
c->gdt[SEG_KCPU] = SEG(STA_W, &c->cpu, 8, 0);
Four segments for kernel and userspace code and data, one for TSS, nice and simple code, clear logic, great OS for education.
To read
- Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3a
- Gustavo Duartes articles are great as usual (why he’s not writing anymore?):
- OsDev wiki topics for GDT: