On dynamic arrays
June 26, 2016
I was reading Skiena’s “Algorithm Design Manual”, it’s an amazing book by the way, and run into this comparison (chapter 3.1.3) of linked lists and arrays:
The relative advantages of linked lists over static arrays include:
• Overflow on linked structures can never occur unless the memory is actually full
• Insertions and deletions are simpler than for contiguous (array) lists.
• With large records, moving pointers is easier and faster than moving the items themselves.
while the relative advantages of arrays include:
• Linked structures require extra space for storing pointer fields.
• Linked lists do not allow efficient random access to items.
• Arrays allow better memory locality and cache performance than random pointer jumping.
Mr. Skiena gives a comprehensive comparison but unfortunately doesn’t stress enough the last point. As a system programmer, I know that memory access patterns, effective caching and exploiting CPU pipelines can be and is a game changer, and I would like to illustrate it here.
Let’s make a simple test and compare the performance of linked list and dynamic array data structures on basic operations like inserting and searching.
I’ll use Java as a perfect computer science playground tool. In Java, we have
LinkedList and ArrayList - classes that implement linked list and dynamic
array correspondingly, and both implement the same List interface.
Our tests will include:
- Allocation by inserting 1 million random elements.
- Inserting 10 000 elements in random places.
- Inserting 10 000 elements to the head.
- Inserting 10 000 elements to the tail.
- Searching for a 10 000 random elements.
- Deleting all elements.
Sources are at my CS playground in ds/list-perf
dir. There is Maven
project, so you can just do mvn package and get a jar. Tests are quite simple,
for example, here is the random insertion test:
package com.dzyoba.alex;
import java.util.List;
import java.util.Random;
public class TestInsert implements Runnable {
private List<Integer> list;
private int listSize;
private int randomOps;
public TestInsert(List<Integer> list, int randomOps) {
this.list = list;
this.randomOps = randomOps;
}
public void run() {
int index, element;
int listSize = list.size();
Random randGen = new Random();
for (int i = 0; i < randomOps; i++) {
index = randGen.nextInt(listSize);
element = randGen.nextInt(listSize);
list.add(index, element);
}
}
}
It’s working using List interface (yay, polymorphism!), so we can pass
LinkedList and ArrayList without changing anything. It runs tests in the
order mentioned above (allocation->insertions->search->delete) several times and
calculating min/median/max of all test results.
Alright, enough words, let’s run it!
$ time java -cp target/TestList-1.0-SNAPSHOT.jar com.dzyoba.alex.TestList
Testing LinkedList
Allocation: 7/22/442 ms
Insert: 9428/11125/23574 ms
InsertHead: 0/1/3 ms
InsertTail: 0/1/2 ms
Search: 25069/27087/50759 ms
Delete: 6/7/13 ms
------------------
Testing ArrayList
Allocation: 6/8/29 ms
Insert: 1676/1761/2254 ms
InsertHead: 4333/4615/5855 ms
InsertTail: 0/0/2 ms
Search: 9321/9579/11140 ms
Delete: 0/1/5 ms
real 10m31.750s
user 10m36.737s
sys 0m1.011s
You can see with the naked eye that LinkedList loses. But let me show you nice
box plots:
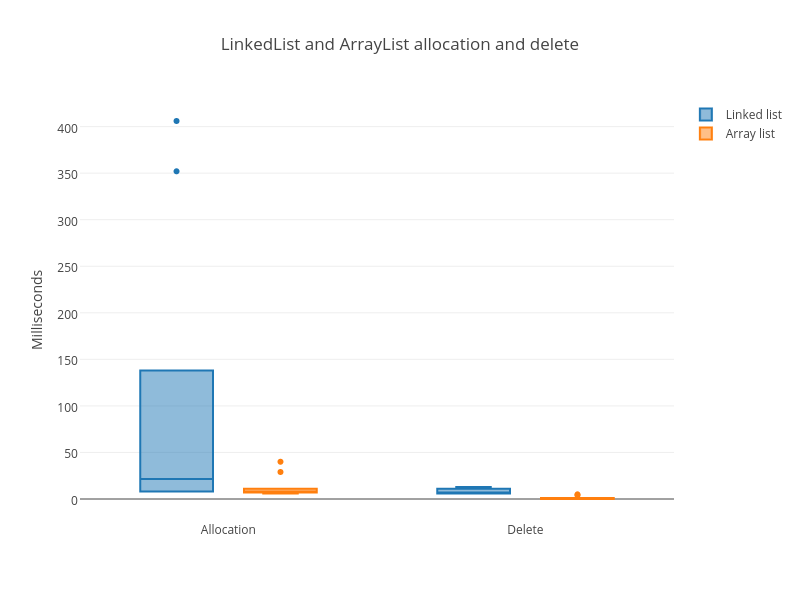
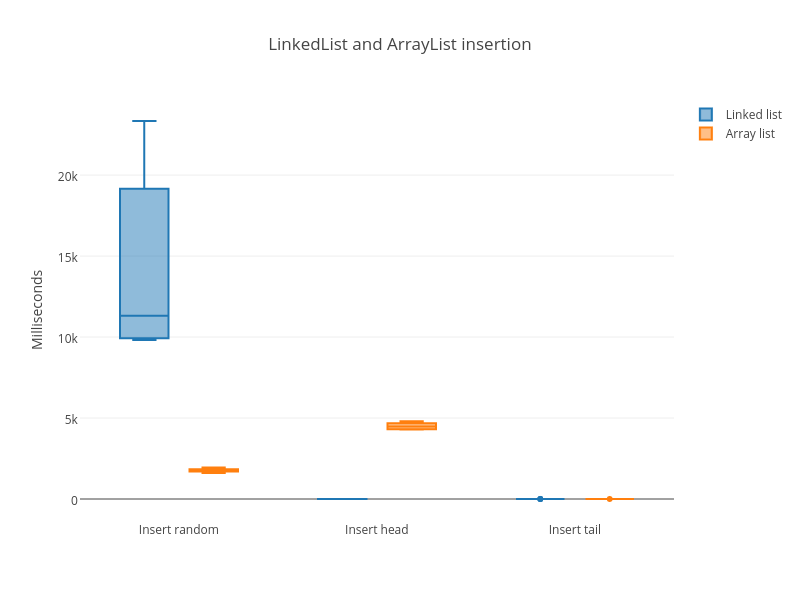
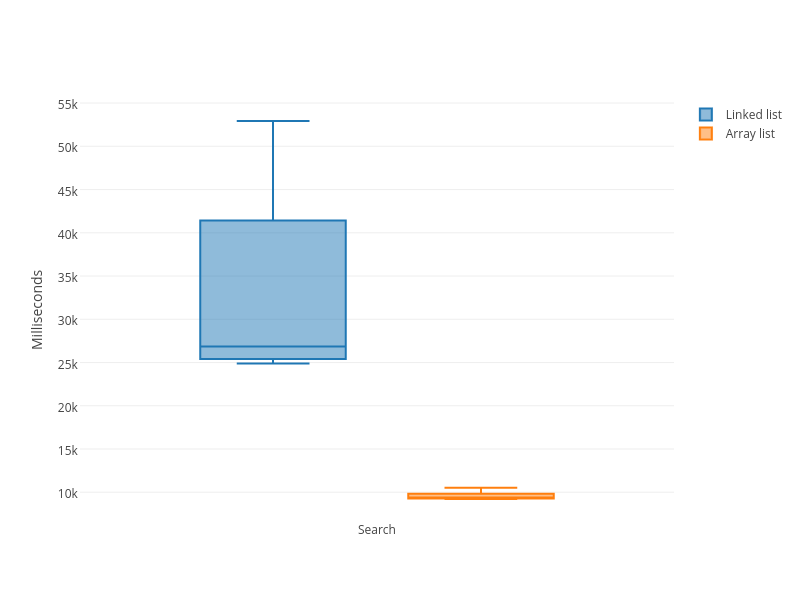
And here is the link to all tests combined
In all operations, LinkedList sucks horribly. The only exception is the insert
to the head, but that’s a playing against worst-case of dynamic array – it has
to copy the whole array every time.
To explain this, we’ll dive a little bit into implementation. I’ll use OpenJDK sources of Java 8.
So, ArrayList and LinkedList sources are in
src/share/classes/java/util
LinkedList in Java is implemented as a doubly-linked list via Node inner
class:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
Now, let’s look at what’s happening under the hood in the simple allocation test.
for (int i = 0; i < listSize; i++) {
list.add(i);
}
It invokes
add
method which invokes
linkLast
method in JDK:
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
Essentially, allocation in LinkedList is a constant time operation.
LinkedList class maintains the tail pointer, so to insert it just has to
allocate a new object and update 2 pointers. It shouldn’t be that slow! But
why does it happens? Let’s compare with
ArrayList.
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
ArrayList in Java is, indeed, a dynamic array that increases its size in 1.5
each grow with the initial capacity of 10. Also this //overflow-conscious code is
actually pretty funny. You can read why is that so
here)
The resizing itself is done via
Arrays.copyOf
which calls
System.arraycopy
which is a Java native method. Implementation of native methods is not part of
JDK, it’s a particular JVM function. Let’s grab Hotspot source code and look into it.
Long story short - it’s in
TypeArrayKlass::copy_array
method that invokes
Copy::conjoint_memory_atomic.
This one is looking for alignment, namely there are variant for long, int, short
and bytes(unaligned) copy. We’ll look plain int variant -
conjoint_jints_atomic
which is a wrapper for
pd_conjoint_jints_atomic. This one is OS and CPU
specific. Looking for Linux variant we’ll find a call to
_Copy_conjoint_jints_atomic. And the last one is an assembly beast!
# Support for void Copy::conjoint_jints_atomic(void* from,
# void* to,
# size_t count)
# Equivalent to
# arrayof_conjoint_jints
.p2align 4,,15
.type _Copy_conjoint_jints_atomic,@function
.type _Copy_arrayof_conjoint_jints,@function
_Copy_conjoint_jints_atomic:
_Copy_arrayof_conjoint_jints:
pushl %esi
movl 4+12(%esp),%ecx # count
pushl %edi
movl 8+ 4(%esp),%esi # from
movl 8+ 8(%esp),%edi # to
cmpl %esi,%edi
leal -4(%esi,%ecx,4),%eax # from + count*4 - 4
jbe ci_CopyRight
cmpl %eax,%edi
jbe ci_CopyLeft
ci_CopyRight:
cmpl $32,%ecx
jbe 2f # <= 32 dwords
rep; smovl
popl %edi
popl %esi
ret
.space 10
2: subl %esi,%edi
jmp 4f
.p2align 4,,15
3: movl (%esi),%edx
movl %edx,(%edi,%esi,1)
addl $4,%esi
4: subl $1,%ecx
jge 3b
popl %edi
popl %esi
ret
ci_CopyLeft:
std
leal -4(%edi,%ecx,4),%edi # to + count*4 - 4
cmpl $32,%ecx
ja 4f # > 32 dwords
subl %eax,%edi # eax == from + count*4 - 4
jmp 3f
.p2align 4,,15
2: movl (%eax),%edx
movl %edx,(%edi,%eax,1)
subl $4,%eax
3: subl $1,%ecx
jge 2b
cld
popl %edi
popl %esi
ret
4: movl %eax,%esi # from + count*4 - 4
rep; smovl
cld
popl %edi
popl %esi
ret
The point is not that VM languages are slower, but that random memory access
kills performance. The essence of conjoint_jints_atomic is rep; smovl1. And if CPU really loves something it is rep instructions.
For this, CPU can pipeline, prefetch, cache and do all the things it was built
for - streaming calculations and predictable memory access. Just read the
awesome “Modern Microprocessors. A 90 Minute Guide!”.
What it’s all mean is that for application rep smovl is not really a linear
operation, but somewhat constant. Let’s illustrate the last point. For a list of
1 000 000 elements let’s do insertion to the head of the list for 100, 1000 and
10000 elements. On my machine I’ve got the next samples:
- 100 TestInsertHead: [41, 42, 42, 43, 46]
- 1000 TestInsertHead: [409, 409, 411, 411, 412]
- 10000 TestInsertHead: [4163, 4166, 4175, 4198, 4204]
Each 10 times increase results in the same 10 times increase of operations because it’s “10 * O(1)”.
Experienced developers are engineers and they know that computer science is not software engineering . What’s good in theory might be wrong in practice because you don’t take into account all the factors. To succeed in the real world, knowledge of the underlying system and how it works is incredibly important and can be a game changer.
And it’s not only my opinion, a couple of years ago2 there was a link on Reddit - Bjarne Stroustrup: Why you should avoid LinkedLists. And I agree with his points. But, of course, be sane, don’t blindly trust anyone or anything - measure, measure, measure.
And Here I would like to leave you with my all-time favorite “The Night Watch” by James Mickens.